

Optimize AKS Traffic with externalTrafficPolicy Local
Managing external traffic in Kubernetes clusters can be a complex task, especially when striving to maintain service reliability, optimize performance, and ensure seamless user experiences. With the increasing adoption of Kubernetes in production environments, understanding and implementing best practices for external traffic management when using the Azure Load Balancer has become essential.
In this blog, we delve into the intricacies of Kubernetes externalTrafficPolicy=Local setting and explore strategies to gracefully handle pod shutdowns, rolling updates, and pod distribution. By following these best practices, you can enhance the resilience and reliability of your services while optimizing resource utilization across your AKS clusters.
The Advantages of Local ExternalTrafficPolicy
The key differences between ExternalTrafficPolicy=Local and ExternalTrafficPolicy=Cluster is traffic routing are:
- With Local, only nodes that have healthy pods for the service receive traffic. The node routes the traffic solely to the pods residing on it.
- With Cluster, all nodes are behind the Azure Load Balancer. The incoming external traffic is distributed across all nodes in the cluster—even those that don’t have any pods for the service. Each node then routes the traffic internally to the available pods for that service.
These architectural differences give ExternalTrafficPolicy=Local some key benefits over type cluster including:
1. Localized Impact of Node Downtime: The impact during node downtime is more confined. Specifically:
- Local Mode: Traffic is affected only if the downed node is running a service pod, impacting that pod’s share of the traffic (i.e., 1/N, where N is the total number of service pods).
- Cluster Mode: Not only is the traffic affected on the node running the service pod (1/N), but a downed on any other node also affects an additional 1/M of the traffic, where M is the total number of nodes.
2. Preservation of the Client Source IP: The client’s original IP is maintained because traffic is only routed to nodes hosting healthy pods. This is crucial for security, logging, and analytics.
To learn more, you can refer to Kubernetes Traffic Policies
How externalTrafficPolicy=Local Works
As detailed above, externalTrafficPolicy=Local routes traffic directly to nodes hosting service pods and which meet the health check requirements. Below is an illustration of how this policy works in practice:
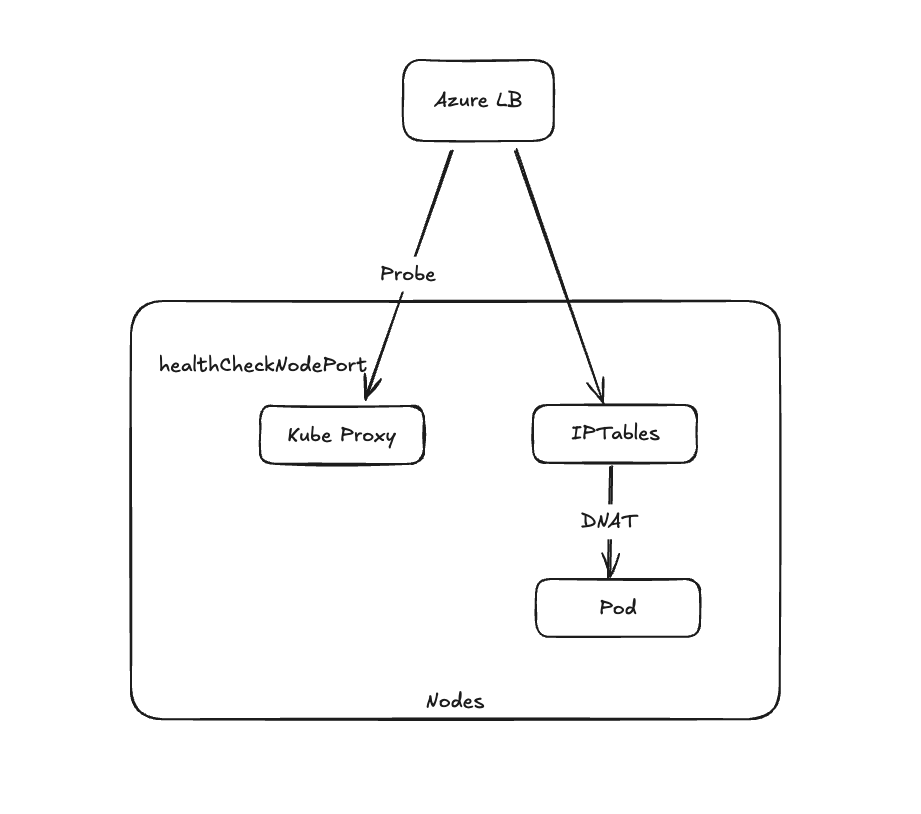
Let’s look into how each of the following components work with the Local Mode:
When you set a Service’s external traffic policy to Local in AKS, you’ll see an additional field in the Service description: HealthCheck NodePort. This is a dedicated NodePort (e.g. port number in the 30000+ range) that Azure’s Standard Load Balancer uses to verify which nodes have healthy pods for this Service.
-
Health Probe on Each Node: Azure automatically configures a health probe on the load balancer that targets the
HealthCheckNodePortacross all nodes in the LB’s backend pool. Kubernetes ensures that this port only returns a successful response on nodes that are running at least one ready pod for the Service. Nodes with no pods for that Service will fail the health check. -
Load Balancer Backend Pool: With
externalTrafficPolicy=Local, all cluster nodes are listed in the LB’s backend pool. But due to the health probes, nodes without a Service pod are marked unhealthy and won’t receive traffic. Only nodes with healthy pods respond to the probe and remain in rotation. By contrast, inClustermode, every node responds (since even if it has no pod, kube-proxy will forward the traffic), so the LB sees all nodes as healthy. Thekube-proxycomponent manages this port and ensures it responds in accordance with the trafficpolicy selected. -
IPTables Rules: IPTables rules are configured to only forward incoming traffic from the Azure Load Balancer (ALB) directly to pods running on the same node. These rules ensure that traffic is never forwarded to other nodes. This localized traffic routing reduces latency and ensures that external connections continue to be served even during node update operations.
By combining these mechanisms, externalTrafficPolicy=Local provides a robust way to manage external traffic while maintaining source IP visibility and ensuring traffic is routed to healthy pods directly.
Best Practices to gracefully close existing connections and shut service pods
Gracefully handling pod shutdowns is critical to maintaining service reliability and avoiding disruptions, especially in scenarios involving HTTP keep-alive connections or long-lived client sessions. Without a graceful shutdown process, external customers could see errors like - connection refused and connection reset by peer during node related events.
Below are detailed best practices for how pods can handle Kubernetes initiated termination requests (eg: pod evictions or a scale down) to ensure a smooth shutdown process.
Preventing New Connections to an Unhealthy Pod when using externalTrafficPolicy=Local
To avoid routing new requests to a pod that is in the process of shutting down, it is important to manage its health status effectively. The below image shows the timeline for a pod receiving a TERM signal and gracefully shutting down without impact on external traffic:
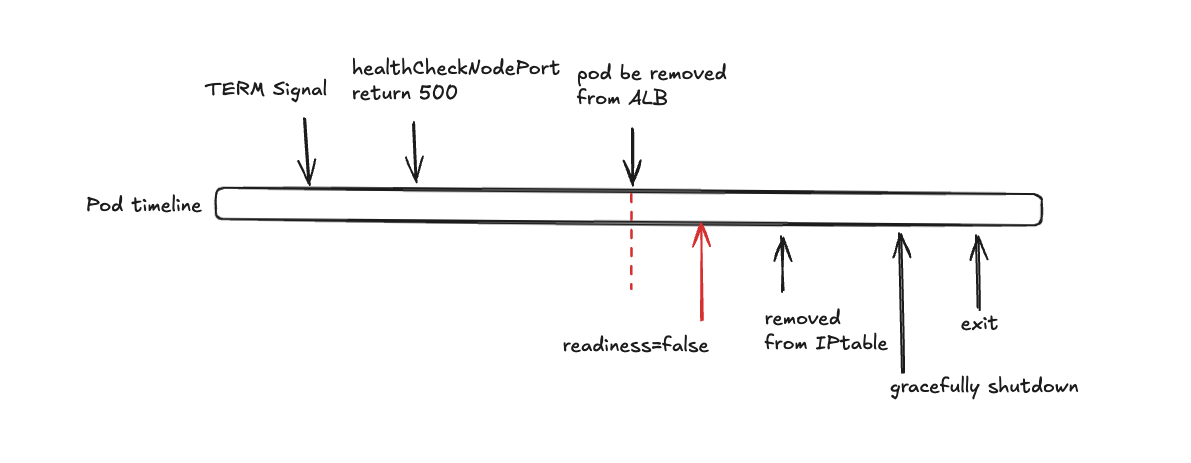
-
Immediate Health Check Response: As soon as a pod is marked for deletion, kube-proxy’s healthCheckNodePort begins returning HTTP 500. This immediately signals external load balancers that the pod is no longer healthy and should stop receiving traffic.
-
Load Balancer Probe Delay: External load balancers will take a few seconds (upto 10 sec) to detect the unhealthy status of a pod. During this time, the pod might still receive new connections.
To ensure your pods follow a similar timeline to gracefully shutdown, make sure to assess the following:
-
Delay Termination: After receiving the
TERMsignal, we recommend your application wait for at least 10 seconds before proceeding with shutdown tasks (to address the Load balancer probe delay). This can be achieved using apreStophook in Kubernetes.Note: When using annotations
service.beta.kubernetes.io/azure-load-balancer-health-probe-intervaland/orservice.beta.kubernetes.io/azure-load-balancer-health-probe-num-of-probe, consider changing the wait time to cover the annotation’s needs (see documentation) -
Announce Readiness as
false: The application should update its readiness probe to indicate it is no longer ready to serve traffic after the above delay has completed. This allows Kubernetes to stop routing new connections to the pod after the load balancer removes it from the list of active pods. -
Gracefully Close Existing Connections: The application should close all active connections, ensuring that no in-flight requests are dropped.
-
Exit the Process: Once all shutdown tasks are complete, the application should terminate its process cleanly.
Gracefully Closing Existing Connections
When a pod is shutting down (receiving the TERM signal), it is essential to ensure that existing client connections are closed properly to avoid abrupt disconnections or errors. Failing to handle this gracefully could result in clients encountering errors like connection reset by peer or connection refused, leading to a poor user experience and potential service disruptions.
-
For HTTP/1.1 Connections: After receiving the TERM signal, the server should include a Connection: close header in its responses to all active and new incoming requests. This signals to clients that the connection will be closed and should not be reused, allowing idle connections to terminate gracefully. Use Case: Applications serving REST APIs or web traffic where clients rely on persistent connections for performance optimization.
Note: In HTTP/1.1, there is a potential race condition where the server might close an idle connection at the same time the client sends a new request. In such cases, the client must handle this scenario by retrying the request on a new connection.
-
For HTTP/2 Connections: The server should send a
GOAWAYframe to notify clients that the connection is being closed. This allows clients to gracefully terminate the connection and retry requests on a new connection if necessary. Use Case: Applications using gRPC or HTTP/2 for high-performance communication between services or with external clients.
By implementing these best practices, you can minimize disruptions during pod shutdowns, maintain a seamless user experience, and ensure the reliability of your services in production environments.
Best Practices for Rolling Updates and Pod Rotation
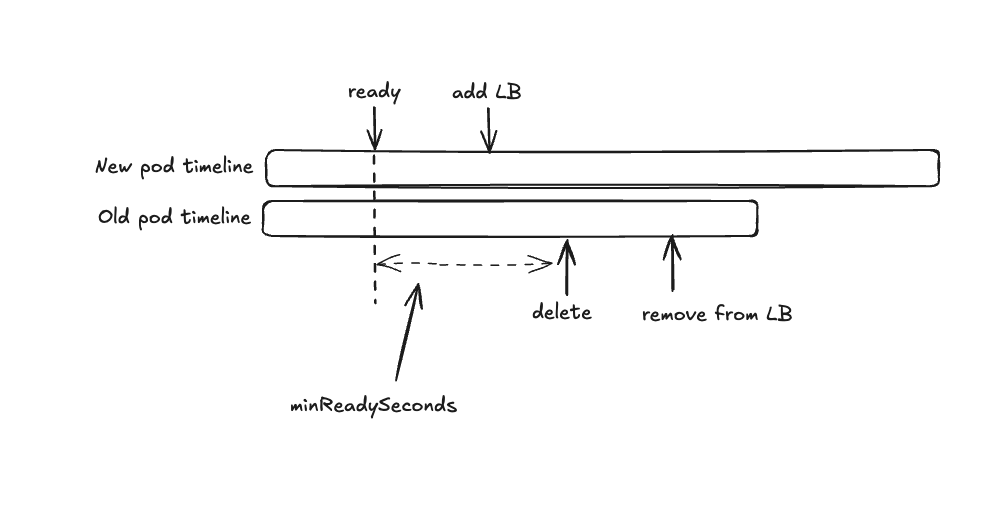
While the above works when a pod is being taken down in isolation, it does not cover cases like upgrades and rolling restarts which require coordination between the time the pod goes down and a new one comes up, ready to serve traffic. To optimize pod rotation, add the following best practice to your deployment:
Set minReadySeconds:
Configure the minReadySeconds parameter in your deployment (we recommend around 10 sec) to introduce a delay before Kubernetes is able to mark the pod as “available” (i.e the pod has been ready long enough that the rolling upgrade can move to the next pod - making it different from the “ready” state which implies the application is ready to receive new connections). This buffer gives the load balancer enough time to register the new pod and start routing traffic to it, while also preventing Kubernetes from deleting the old pod prematurely.
By implementing this strategy, you can achieve smoother rolling updates and maintain a consistent user experience during application changes.
Pod Distribution Best Practices
Achieving an even distribution of pods across nodes is important for load balancing and resource utilization, especially for pods receiving external traffic via externalTrafficPolicy=Local. The diagram below demonstrates an example of uneven pod distribution which leads to imbalanced traffic across pods:
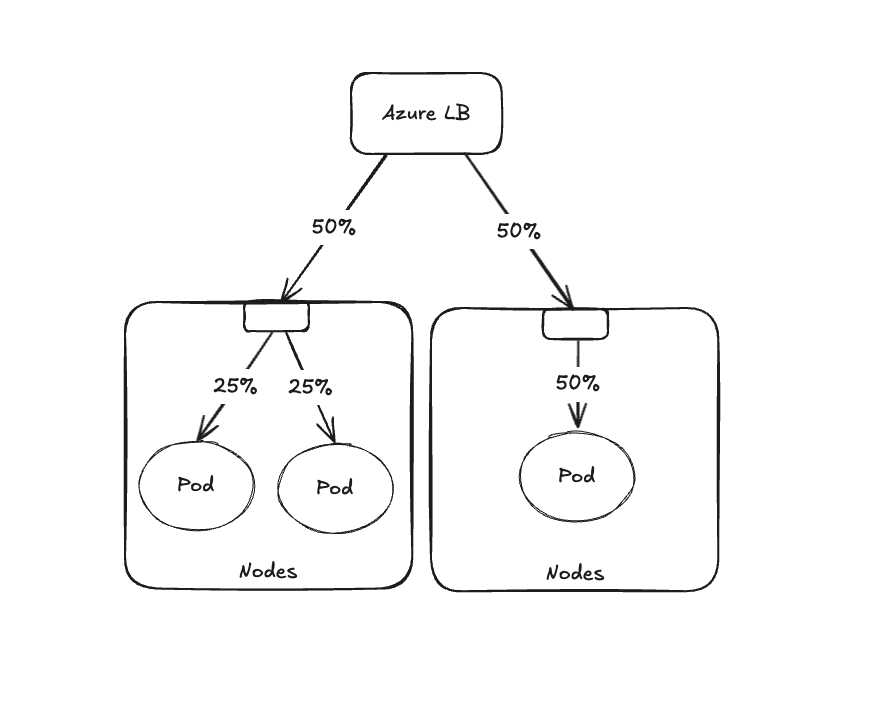
In this situation, even though the load balancer divides the traffic evenly between nodes, the pods on the node with 2 replicas serve 25% of the traffic each, while the pod in the single replica node serves the full 50% of the total traffic.
Below are some best practices you can follow to evenly distribute pods across your nodes based on your workload needs:
- Pod Anti-Affinity:
- Ensures pods with the same label are not scheduled on the same node.
- Requires more nodes than pods, including surge pods during evictions or deployments.
- Topology Spread Constraints:
- Distributes pods as evenly as possible (best effort) across available nodes and zones (specified with the topologyKey).
Note: If your application requires strict spreading of pods (i.e., your ideal behavior is to leave a pod in pending if spread is not possible), you can set the
whenUnsatisfiabletoDoNotSchedule
- Distributes pods as evenly as possible (best effort) across available nodes and zones (specified with the topologyKey).
- MatchLabelKeys:
- Provides fine-grained control over pod scheduling decisions.
- Ensures pods from different deployment versions do not overlap on the same nodes.
For additional best practices, you can refer to Deployment and Cluster Reliability Best Practices for AKS
Conclusion
To conclude, while externalTrafficPolicy=Local is a powerful option for optimizing traffic routing in AKS, it also requires careful planning of your pod lifecycle. With a professional, proactive approach to how your services handle start-up and shutdown, you can reap the benefits of Local traffic policy – getting client IP transparency and efficient routing – without sacrificing reliability during deployments or scaling events. Kubernetes gives us the knobs; it’s up to us as SREs and engineers to turn them correctly for our particular workloads. Happy load balancing!