Performance Tuning AKS for Network Intensive Workloads
Background
As more intelligent applications are deployed and hosted on Azure Kubernetes Service (AKS), network performance becomes increasingly critical to ensuring a seamless user experience. For example, a chatbot server running in an AKS cluster needs to handle high volumes of network traffic with low latency, while retrieving contextual data — such as conversation history and user feedback from a database or cache, and interacting with a LLM (Large Language Model) endpoint through prompt requests and streamed inference responses.
In this blog post, we share how we conducted simple benchmarks to evaluate and compare network performance across various VM (Virtual Machine) SKUs and series. We also provide recommendations on key kernel settings to help you explore the trade-offs between network performance and resource usage.
Benchmark
Our methodology involves conducting tests and measurements to identify key factors affecting network performance for applications running on AKS. We simulated a common use case: a pair of pods communicating in TCP protocol across two different nodes within the same cluster. We measured various performance metrics, including throughput, round-trip time (RTT), and retransmission rate in the presence of packet loss at high bandwidth usage.
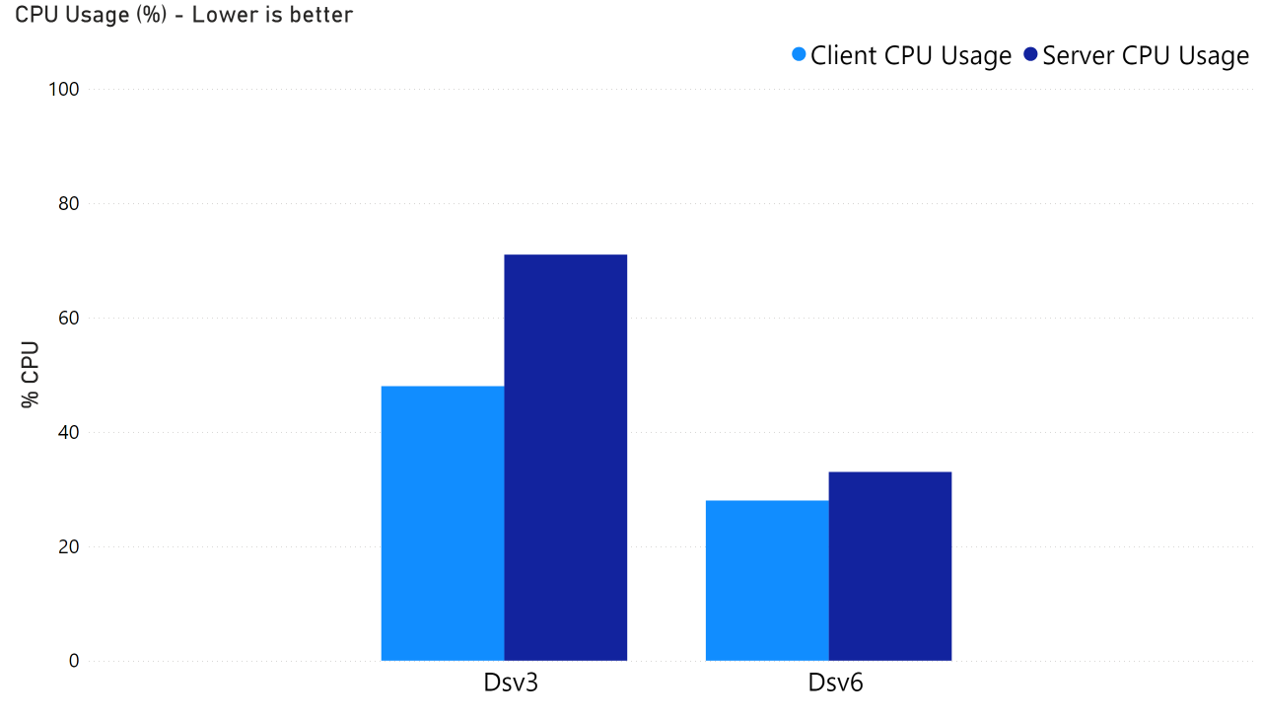
In our experiment, iperf3 was run as a container within Kubernetes pods in the host network namespace on selected nodes to generate single or multiple TCP streams simulating application traffic. All underlying Kubernetes nodes had identical hardware specifications: 48 CPU cores, 192 GB of memory, and were running Linux 5.X kernels. During each test, we also monitor CPU and memory usage of both client and server containers to make sure iperf3 is not resource constrained.
Hardware Matters Most
We compared the test results of Azure’s older generation series Dsv3 and newer generation series Dsv6 on AKS, and observated signifncant network performance difference:
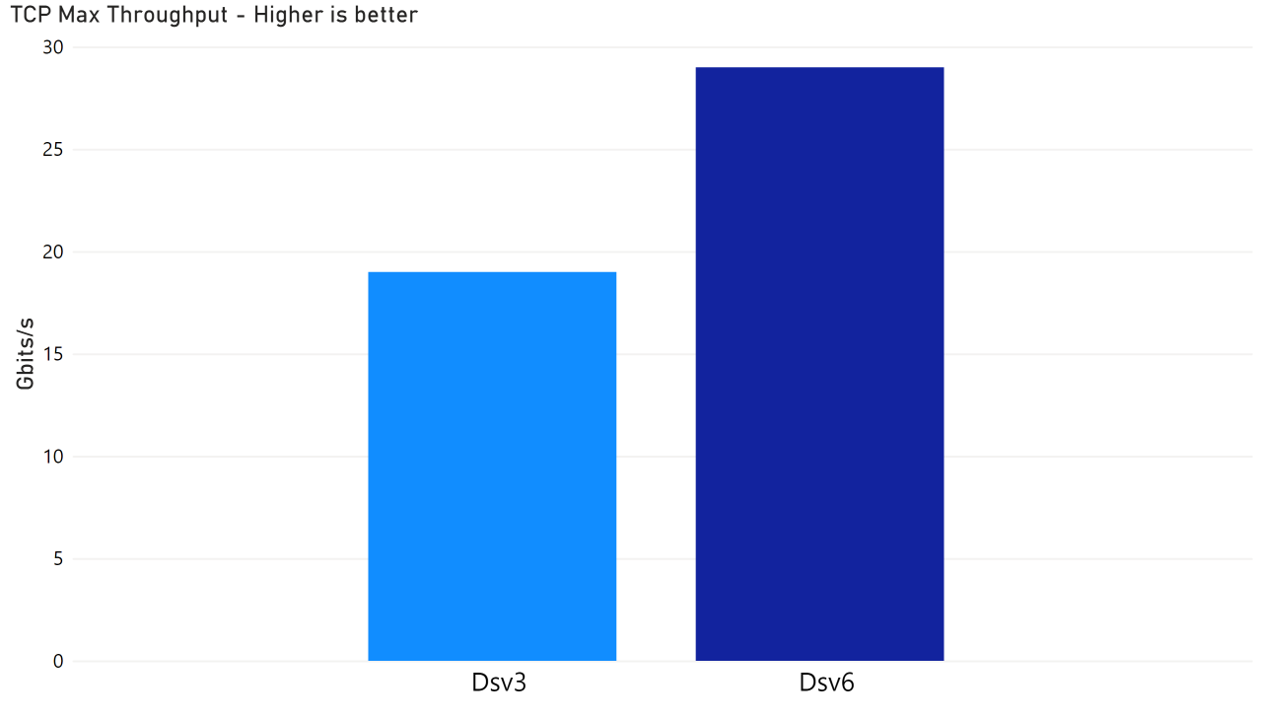
Up to 35% higher throughput for Azure Dsv6 compared to Dsv3 when trying to maximize network bandwidth usage.
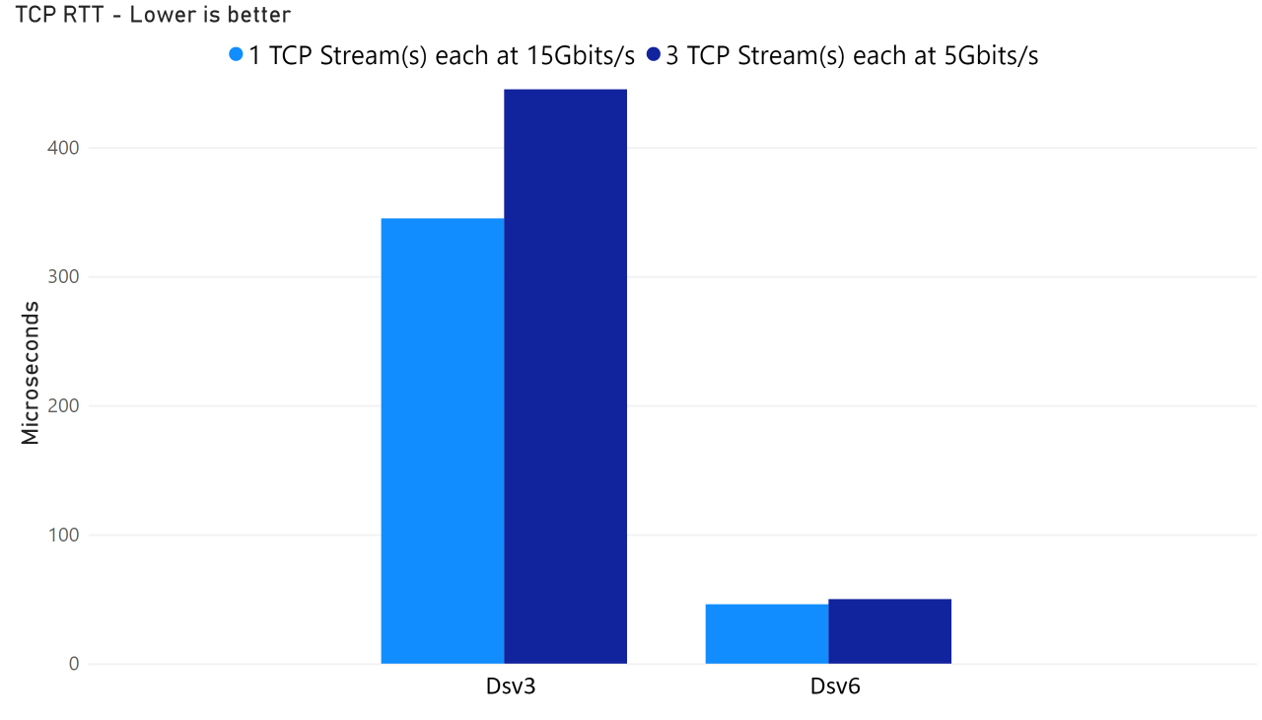
Up to 3x~6x lower RTT for Azure Dsv6 compared to Dsv3 when tests are limited to the same network bandwidth usage.
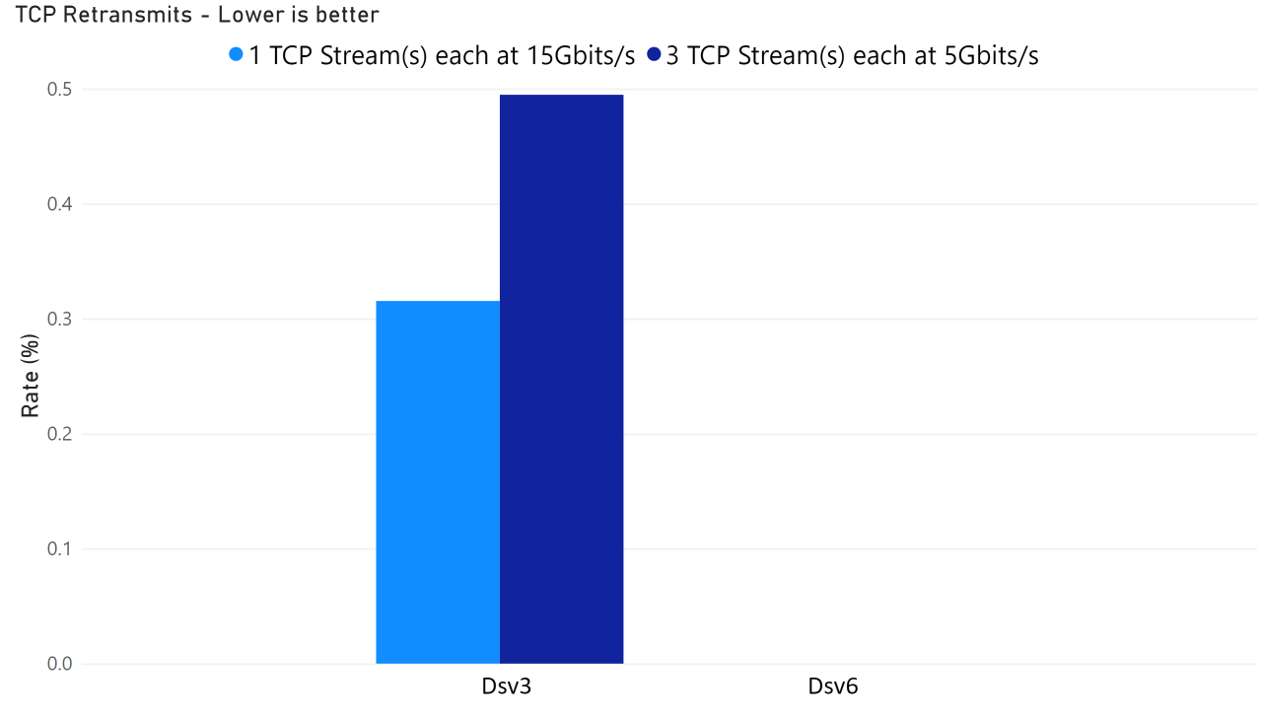
The TCP retransmission rate remained consistently at 0% on Azure Dsv6, while it was noticeably higher on Dsv3.
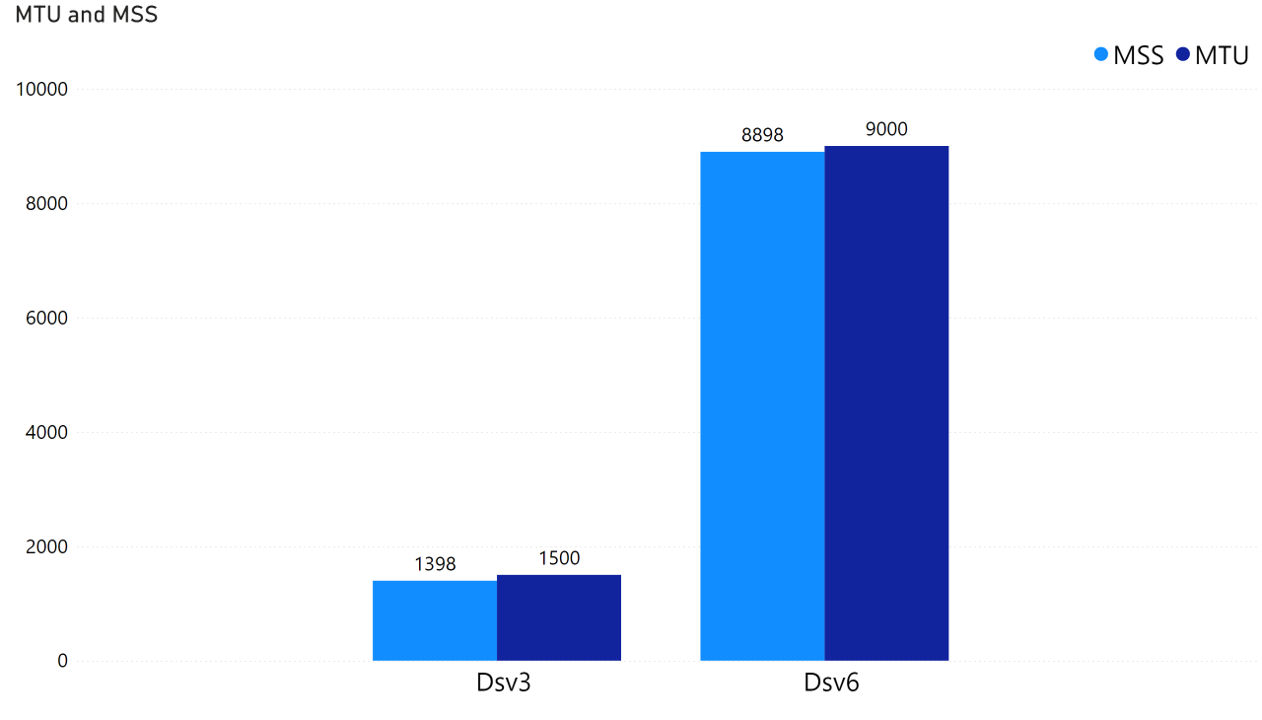
The primary reasons for the significant leap in network performance on Dsv6 is because the next-generation network interface Microsoft Azure Network Adaptor (MANA) supports Jumbo Frame and MTU 9000.
A higher MTU (Maximum Transmission Unit) and MSS (Maximum Segment Size) allow TCP traffic to transmit more data per packet, reducing the total number of packets that need to be processed by network interface and OS kernel. This leads to fewer hardware interrupts, less buffering, and reduced overhead in data movement, ultimately improving overall network efficiency.
We realized there is no way to fully abstract hardware from the application — fundamentally, application network performance is dictated by the capabilities of the underlying CPU, memory, and network interfaces on the physical host. Identifying the appropriate VM SKUs and series is essential to ensure the application meets its networking performance requirements.
The MTU on Azure Dsv6-series VMs is not set to 9000 by default. You can manually adjust the MTU for a specific network interface using the following Linux command:
ip link set $device mtu 9000
To enable Jumbo Frames across all nodes in an AKS cluster, you can deploy a DaemonSet, such as this example. In addition, you can optimize MTU settings dynamically using Path MTU Discovery
Kernel Settings Tuning
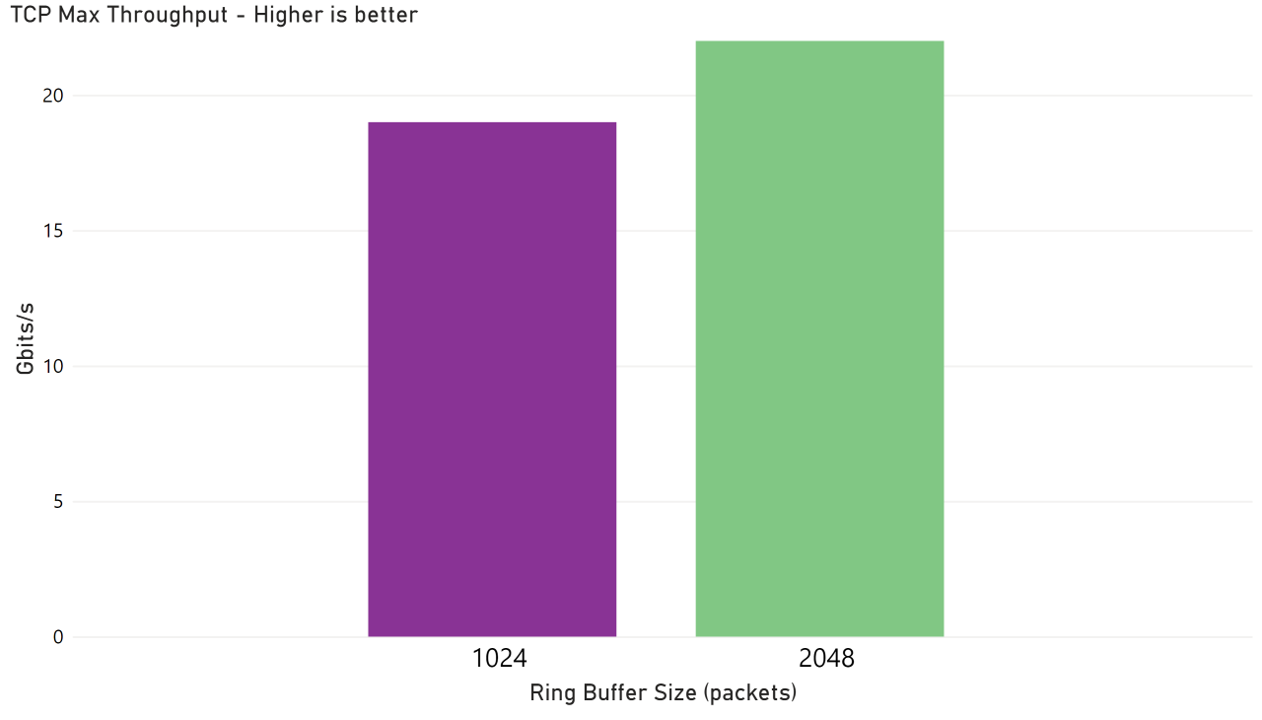
If migrating to a newer VM SKUs or series like Dsv6 isn’t a viable short-term option due to quota limitations or compatibility concerns, kernel-level tuning remains a practical path to improving network performance. In our testing, we explored several tuning parameters and found that adjusting the ring buffer size on the network interface card (NIC) had the most significant impact. As shown below, increasing the NIC receive buffer size from the default 1024 to 2048 packets on a Dsv3 VM resulted in a ~20% improvement in network throughput.
We also observed reductions in both TCP retransmission rate and round-trip time (RTT) under a combined bandwidth load of 15 Gbps. The benefit was especially pronounced when traffic was split across three parallel TCP streams, each operating at 5 Gbps.
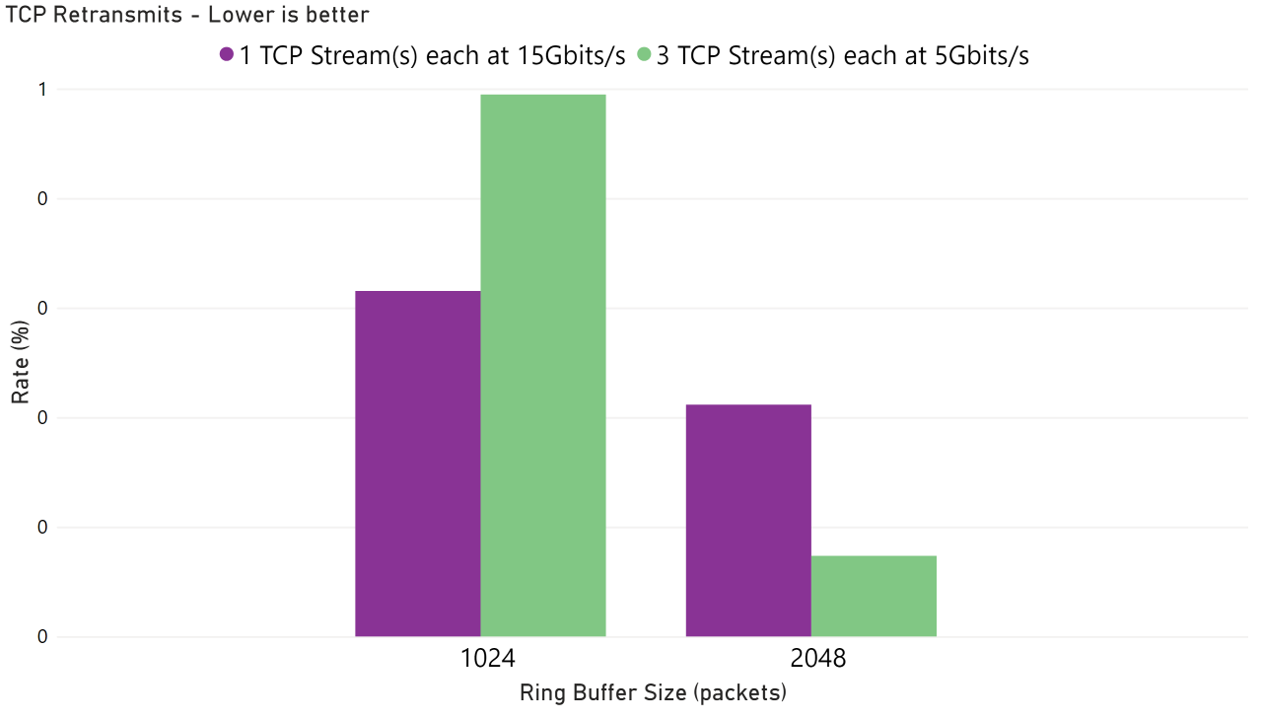
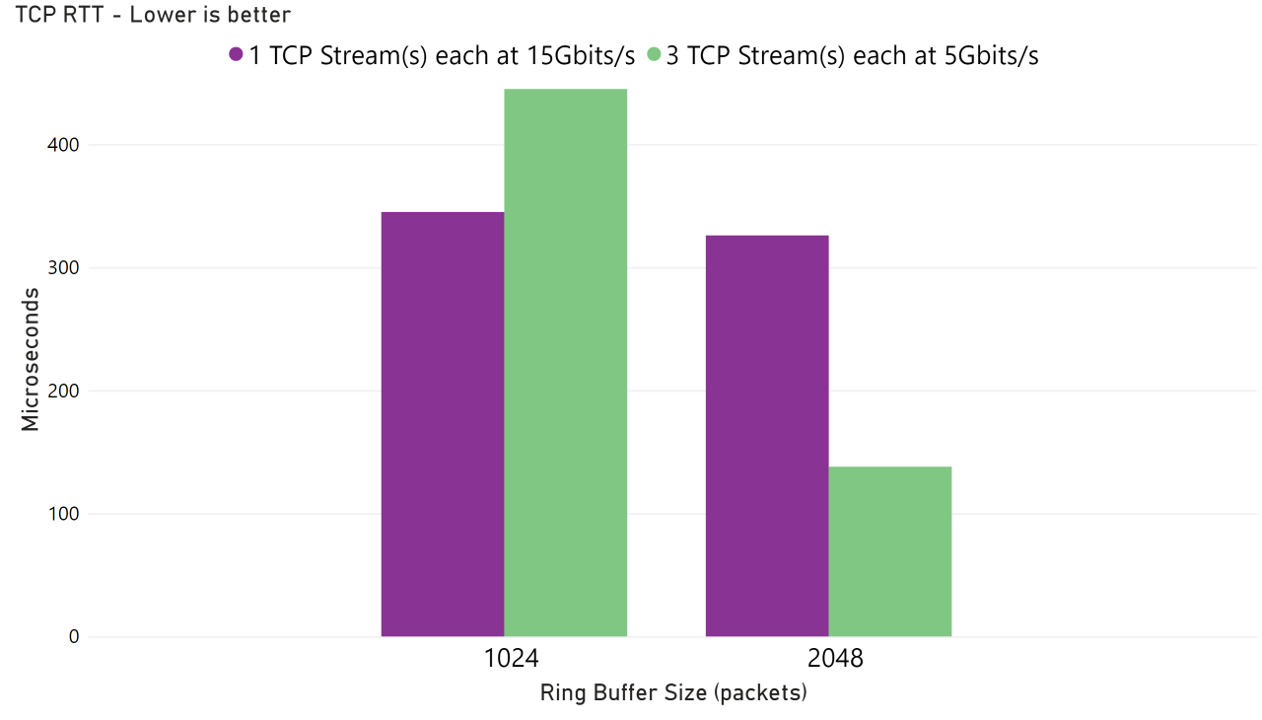
TCP retransmissions often occur when the sender or receiver buffer is too small to handle a surge of packets, resulting in packet drops. For example, if the NIC name is enP28334s1 (typical name for an SR-IOV network interface), you can check how many packets were dropped due to ring buffer overflow with:
ethtool -S enP28334s1 | grep rx_out_of_buffer
If rx_out_of_buffer shows a non-zero value, it indicates that a ring buffer overflow has occurred. To increase the ring buffer size (e.g., to 2048 packets), use:
sudo ethtool -G enP28334s1 rx 2048
Again you can also deploy a daemonSet to enforce consistent ring buffer size across all nodes in AKS cluster following this example.
It’s important to note that increasing the NIC ring buffer size has memory usage implications. Allocating larger buffers means the operating system reserves more memory specifically for handling network traffic, which reduces the amount of memory available for user-space applications. For example, doubling the receive buffer size from 1024 to 2048 packets per descriptor across multiple queues and interfaces can lead to a non-trivial (around 100 MB or more) increase in kernel memory usage — especially on systems with high network concurrency or multiple high-throughput NICs. While this tradeoff can significantly improve network performance, especially under high load, it should be balanced against the memory demands of the application workload running on the same VM.
Conclusion
Achieving optimal network performance on AKS requires a combination of choosing the right VM SKUs and series and fine-tuning kernel-level parameters. By understanding the trade-offs and evaluating different options, AKS users can unlock meaningful improvements in network performance and application responsiveness. Next we plan to expand our benchmarks to include newer Linux 6.x kernels, which incorporate recent networking enhancements. We also intend to measure and analyze the performance implications of container networking solutions (such as Cilium), and to explore additional optimization strategies. Please let us know if there are specific scenarios, workloads, or networking configurations you’d like to see included in future work.