

From 7B to 70B+: Serving giant LLMs efficiently with KAITO and ACStor v2
XL-size large language models (LLMs) are quickly evolving from experimental tools to essential infrastructure. Their flexibility, ease of integration, and growing range of capabilities are positioning them as core components of modern software systems.
Massive LLMs power virtual assistants and recommendations across social media, UI/UX design tooling and self-learning platforms. But how do they differ from your average language model? And how do you get the best bang for your buck running them at scale?
Let’s unpack why large models matter and how Kubernetes, paired with NVMe local storage, accelerates intelligent app development.
Aren’t LLMs large enough?
Large models aren’t just big for show — they’re smart, efficient, and versatile thanks to:
- Efficient transformer architectures powering them
- Compatibility with high-performance inference libraries like vLLM
- Ability to handle long-context memory effectively, allowing them to score well on tasks like instructions, coding, math, and multilingual understanding (check out HuggingFace’s Open LLM Leaderboard to learn more)
Running these XL-size LLMs at scale can be more cost-effective than relying on commercial APIs, if you play your cards right.
When self-hosting big models makes sense 💡
Self-hosting LLMs on Kubernetes is growing in popularity for organizations that are:
- Running lots of inference: batch jobs, chatbots, agents, or apps
- Have access to commercial GPUs like NVIDIA H100 or A100
- Want to avoid per-token API fees (which easily skyrocket costs at scale)
- Keen to fine-tune or customize the model — something closed APIs usually block
- Have sensitive or proprietary data to keep ring-fenced and protected from accidental exposure through third-party logs
Using KAITO for self-hosting
Self-hosting with the Kubernetes AI Toolchain Operator (KAITO) helps you achieve all this and more! KAITO is a CNCF Sandbox project that simplifies and optimizes your inference and tuning workloads on Kubernetes. By default, it integrates with vLLM, a high-throughput LLM inference engine optimized for serving large models efficiently.
vLLM supports quantized models, reducing memory/GPU requirements drastically without major accuracy trade-offs. KAITO’s modular, plug-and-play setup allows you to go from model selection to production-grade API quickly:
- Out-of-the-box OpenAI-compatible API means you can swap in KAITO with minimal application-side changes.
- Built-in support for prompt formatting, batching, and streaming responses.
- Self-hosting with KAITO on your AKS cluster ensures data never leaves your organization’s controlled environment, ideal for highly regulated industries (finance, healthcare, defense) where cloud LLM APIs may be restricted due to compliance.
The catch? Managing huge model weights 🏋️♂️
Some models come with massive weight files, and even when fully quantized can weigh hundreds of gigabytes (based on model type and version). Handling and deploying such model serving workloads isn’t trivial, especially if you want reproducible, scalable workflows on Kubernetes.
KAITO balances simplicity and efficiency by using container images to manage most LLMs - but it can become difficult to distribute large model files that result in heavy-weight images.
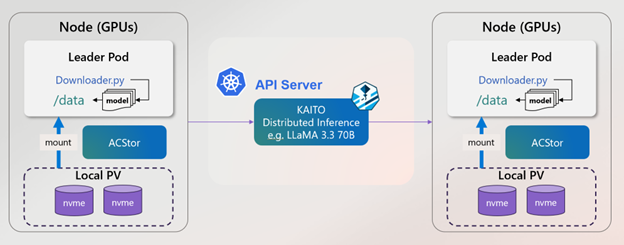
Luckily, KAITO inferencing now supports these model weights with the power of a local file cache and striped Non-Volatile Memory Express (NVMe) PersistentVolume managed by Azure Container Storage.
A local file cache significantly reduces latency during model downloads and reads, enhances reliability with persistent storage and avoids repetitive downloads after container restarts - all without extra storage fees!
What is Azure Container Storage?
Azure Container Storage (ACStor) is a cloud-based volume management, deployment, and orchestration service built natively for containers. It integrates with Kubernetes, allowing you to dynamically and automatically provision persistent volumes to store data for stateful applications running on Kubernetes clusters.
The latest version of this project, ACStor v2, is purpose-built for AI and high-performance computing (HPC) workloads that demand ultra-fast data processing on local NVMe disks. It delivers performance close to raw NVMe speeds, all while providing seamless Kubernetes-native operations.
We’re excited to share that these capabilities are now available in KAITO through early integration. When deployed with KAITO, ACStor v2 provisions striped volumes across local NVMe disks, serving large model files efficiently.
How does this work?
- ACStor v2 aggregates local NVMe drives (available by default in several Azure GPU-enabled VM sizes) as Kubernetes PersistentVolumes (PVs)
- Bypasses network storage bottlenecks for ultra-low latency & high IOPS & high throughput - ideal for AI inference at scale
- Abstracts multiple NVMe drives into (as low as) a single persistent volume, so pods automatically land on nodes with maximum fast storage
- Supports StatefulSets to handle stateful workloads and edge data pipelines smoothly
Why is ACStor v2 ideal for distributed inference with KAITO?
| Benefit | Why it Matters |
|---|---|
| ⚡Performance | Max throughput & IOPS of local NVMe SSDs |
| 🎯Data Locality | Pods get scheduled where storage is available, avoiding failures |
| 💸 Zero added costs | Local storage used by default to avoid external storage fees |
| 📦Kubernetes Native | Full CSI support, PVC lifecycle management, and integration with AKS/VMSS |
| 🔁 Repeatability | Ideal for ML pipelines and reproducible runs |
To test this out, we performed a performance benchmark test on the Llama-3.1-8B-Instruct LLM:
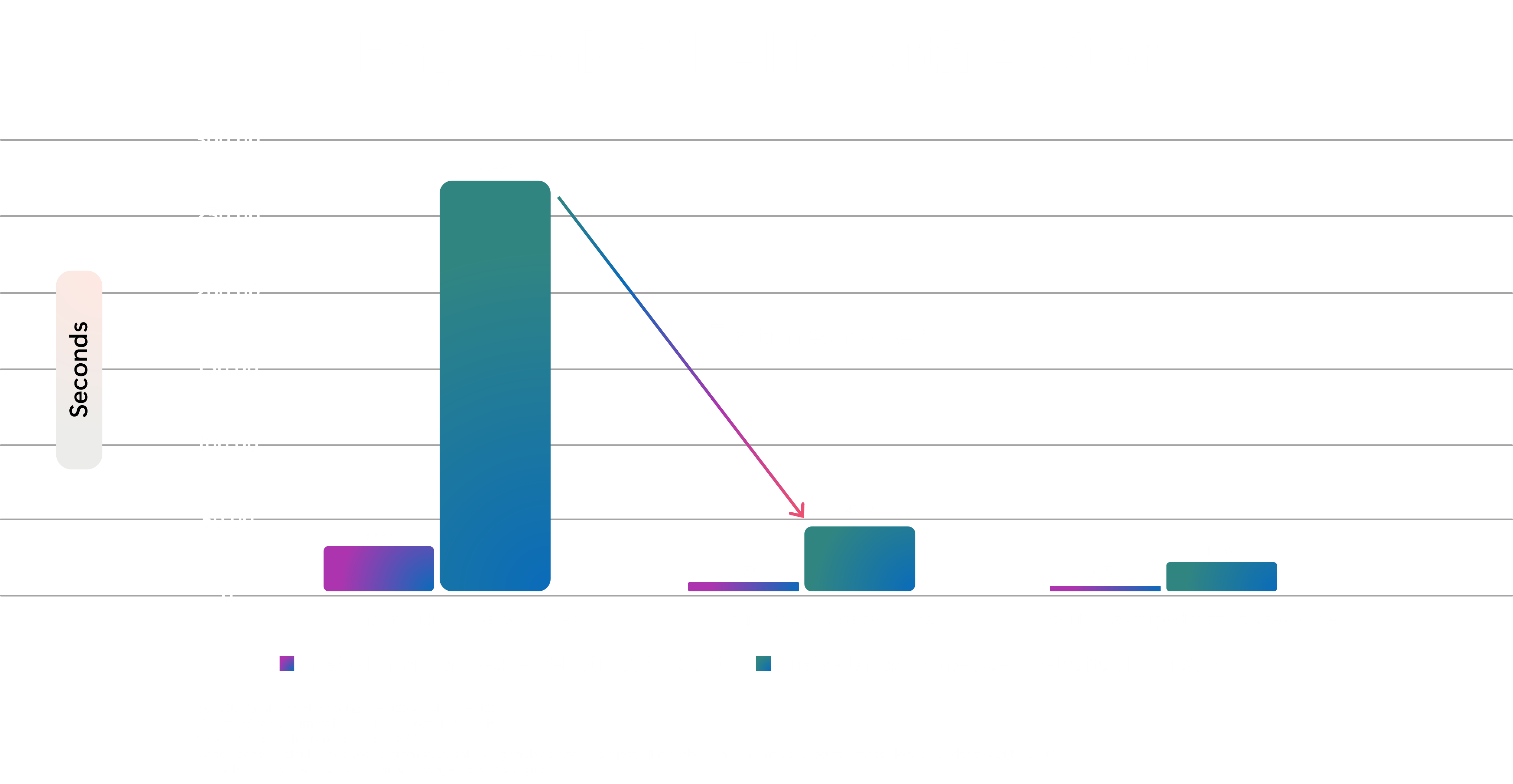
We see over a 5X improvement in model file loading performance when using ACStor v2 with a locally striped NVMe volume, compared to using an ephemeral OS disk!
Ready to dive in? Try LLaMA 3.3 70B today on your AKS cluster
Using this KAITO inference workspace, you’ll leverage NVMe local storage to serve a model as large as LLaMA 3.3 70B LLM (140GB in size) easier and more efficient than ever on AKS. The Llama 3.3 70B tuned model is optimized for multilingual dialogue use cases and outperforms many of the available open source and closed chat models on common industry benchmarks. You get fast inference, scalable deployments, and complete control over your AI stack – now available in open-source KAITO v0.5.0 and coming soon to the AKS managed add-on experience.
For teams looking to adopt Azure Container Storage v2 directly in their own Kubernetes environment, a standalone Kubernetes extension is scheduled for release by September 2025. Stay tuned for more updates!
We want your feedback
Want your favorite XL-size large language model supported with KAITO? Jump in and submit your feature requests to the Upstream project roadmap!