Pair llm-d Inference with KAITO RAG Advanced Search to Enhance your AI Workflows


Overview
In this blog, we'll guide you through setting up an OpenAI API compatible inference endpoint with llm-d and integrating with retrieval- augmented generation (RAG) on AKS. This blog will showcase its value in a key finance use case: indexing the latest SEC 10-K filings for the two S&P 500 companies and querying them. We’ll also highlight the benefits of llm-d based on its architecture and its synergy with RAG.
Introduction
Deploying large language models (LLMs) efficiently, while leveraging private data for context-aware responses, is critical for modern AI applications. Retrieval-Augmented Generation (RAG) combines an LLM with a retriever that pulls in relevant context from your own data (documents, codebases, Wiki pages). This enables scalable, adaptive applications that can respond with domain-specific knowledge simply by updating the underlying data store.
But there’s a catch:
Setting up a RAG pipeline involves infrastructure: vector databases, LLM inference, embedding models, and orchestration - what do these components do?
| RAG component | Purpose | Example |
|---|---|---|
| Vector store | Stores text data (documents, FAQs, etc.) in a vector format, or numerical representations of meaning. This allows the system to find relevant pieces of information, even if the user’s question uses different words than the original text (semantic search) | FAISS (Facebook AI Similarity Search) is widely used and is like a memory system that understands meaning and not just keywords |
| Embedding model | Converts text (like a phrase or sentence) into a vector that captures the meaning of the text. Even if the words in different searches don’t match exactly, an embedding model can produce similar vectors that indicate the system sees that they are semantically close | Sentence-BERT (sBERT) and HuggingFace embedding models |
| Retriever + LLM | The retriever finds useful information to help the LLM give a more accurate or update-to-date answer. Together, they make the RAG system flexible and grounded in real, relevant data and not just what the model memorized. | LlamaIndex and LangChain offer open-source retrievers that are useful for different types of data |
There is where Kubernetes AI Toolchain Operator (KAITO) RAGEngine brings cloud- native agility to AI application development. KAITO is a CNCF Sandbox project that makes it easy to deploy, serve, and scale LLMs on Kubernetes, without needing to become a DevOps expert. Using RAGEngine, you can quickly stand up a service that indexes documents and queries them in conjunction with an existing LLM inference endpoint. This enables your large language model to answer questions based on your own private content.
By automatically configuring and orchestrating the RAG pipeline on Kubernetes, KAITO lets developers focus on building high-impact AI apps, while the engine helps cluster operators and platform engineers handle scaling, rapid iteration, and real-time data grounding.
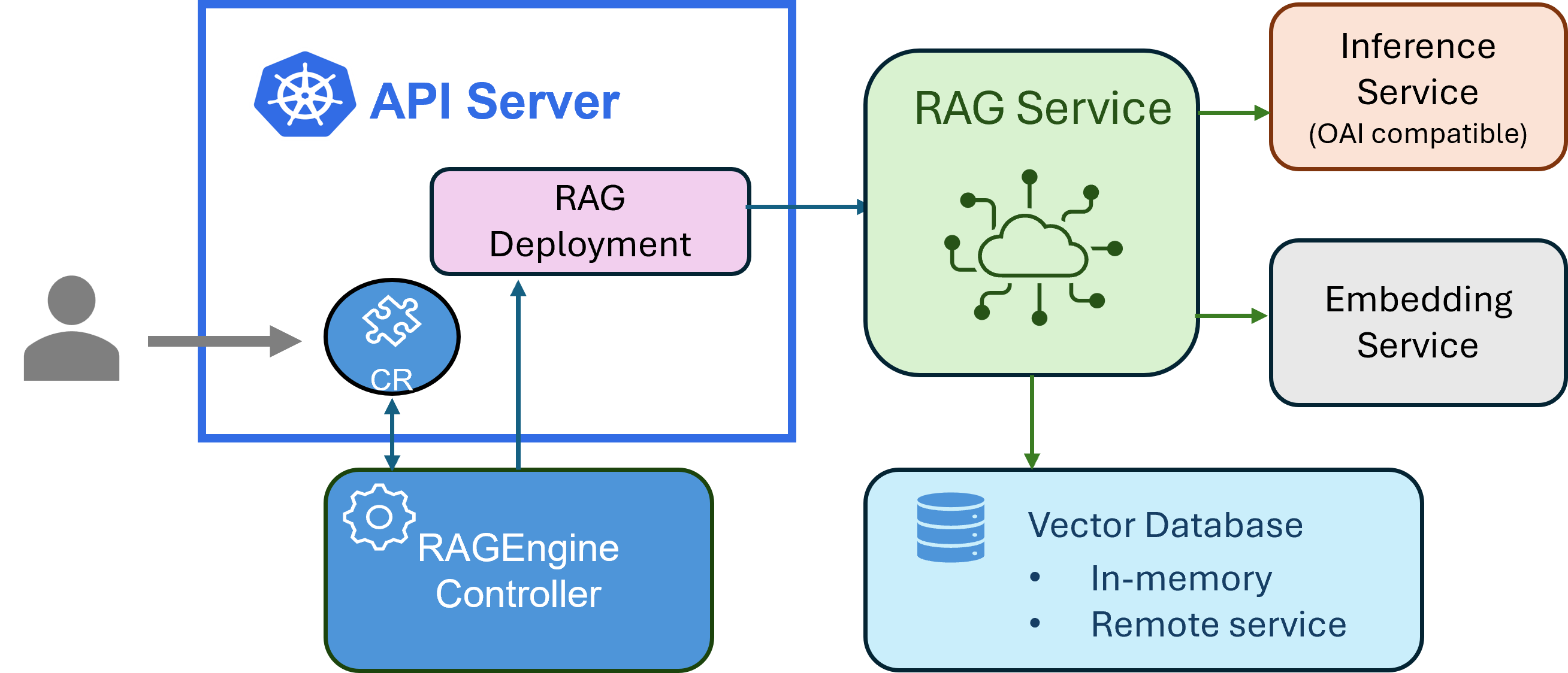
The RAGEngine preset gives you an end-to-end RAG pipeline out of the box, including:
- FAISS as the default, configurable vector store vector store
- BAAI/bge-small-en-v1.5 as the default, configurable embedding model to index your documents
- llama_index as the LLM-based document retrieval framework
- Any OpenAI API compatible LLM inference endpoint to process retrieved documents as context and user queries in natural language
In this blog, the inference endpoint will be provisioned via the llm- d framework.
Both llm-d and RAGEngine are deployed as open-source
solutions in the following example, and are not currently managed on AKS.
Quick vocab check
Before diving in, here's a quick breakdown of terms used with regard to llm-d that will clarify the steps ahead:
- Prefill Stage: The initial phase of LLM inference where the model processes the complete input prompt, computing attention and embeddings to establish the internal context for generation.
- Decode Stage: The autoregressive phase of LLM inference where the model generates output tokens sequentially, one at a time, based on the context from the prefill stage.
- Prefill/Decode (P/D) Disaggregation: The optimization technique of distributing the computationally intensive prefill stage and the lighter, iterative decode stage across separate hardware resources to enhance efficiency and inference speed.
- KV Cache (Key-Value Cache): Stores key and value tensors from the prefill stage’s attention computations, enabling the decode stage to reuse these results for faster token generation, with reduced computational overhead.
Benefits of llm-d and its intersection with RAG
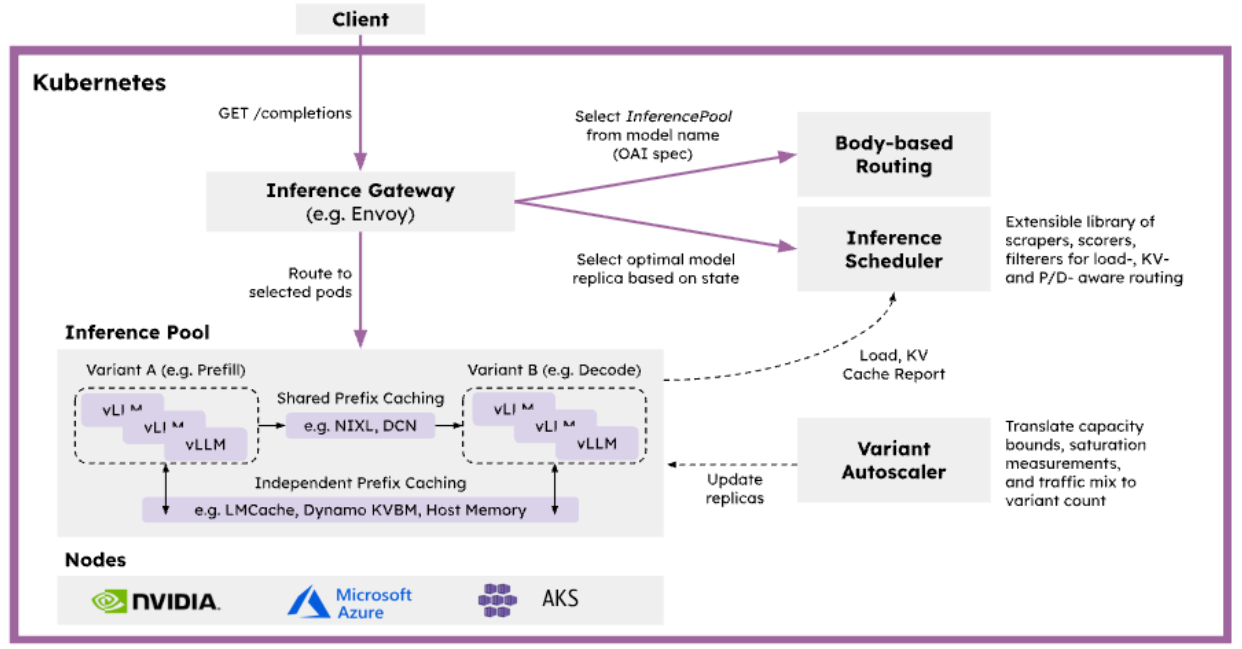
The llm-d framework, built on open-source technologies like vLLM, Gateway API Inference Extension (GAIE), and NIXL, is a Kubernetes-native distributed inference serving stack for serving LLMs at scale. As detailed in the llm-d documentation, it provides several key benefits, particularly when paired with RAG workflows, which often involve long context to keep LLMs up to date.
| llm-d feature | What it does | Benefits to RAG workflows |
|---|---|---|
| Prefill/Decode (P/D) Disaggregation | Separates the compute-heavy prefill stage (KV cache building) from the decode stage (autoregressive token generation) on dedicated GPUs, where each GPU pool can be independently scheduled and scaled | Optimizes throughput for long contexts; prevents resource contention for concurrent requests when processing long RAG queries; enables flexible scaling and lowers time-to-first-token (TTFT) and improves overall token output time (TPOT) |
| Intelligent routing (via Gateway API Inference Extension's Endpoint Picker) | Schedules requests based not only on server queue length and available KV cache size, but also prefix cache hit probability. Maximize the reuse of KV cache for queries with overlapping system prompts and common context retrieved from the vector store | Minimizes latency; enables efficient reuse of KV cache for similar or repeated contexts; handles RAG queries of mixed context length and structure robustly |
| Disaggregated KV cache management | Offloads KV cache across local or remote stores, with orchestration from decode-sidecar and advanced cache eviction policies for efficient memory use | Supports much longer input contexts and multiple concurrent sessions with reduced GPU memory overhead, enabling scalability for large RAG pipelines |
Let’s get started: KAITO RAGEngine backed by llm-d with P/D Disaggregation
With the prerequisites covered, this guide will dive into the creation of two distinct but related endpoints:
-
Inference Endpoint: an OpenAI API compatible inference service in Kubernetes, created by the llm-d stack. Jump to the llm-d inference endpoint section in our GitHub repository to set it up.
-
RAG Endpoint: a RAG service provisioned by KAITO with the inference endpoint pointed to step (1) for users to efficiently index and query their documents. Check out the steps in this RAG endpoint GitHub cookbook section to spin up and verify your RAGEngine workspace, which includes a YAML manifest that looks like:
apiVersion: kaito.sh/v1alpha1
kind: RAGEngine
metadata:
name: ragengine-llm-d
spec:
compute:
instanceType: "Standard_D2s_v4"
labelSelector:
matchLabels:
node.kubernetes.io/instance-type: Standard_D2s_v4
embedding:
local:
modelID: "BAAI/bge-small-en-v1.5"
inferenceService:
url: "http://<inference-url>/v1/chat/completions"
This RAG service only requires general-purpose
compute, like the Azure Standard_DS2_v4 SKU shown above,
which often provides a more cost-effective and accessible
alternative to the GPU-intensive process of continuous
fine-tuning.
Practical Example: Indexing and Querying 10-K Filings
Now, we'll pair llm-d inference with KAITO RAGEngine to index the latest SEC 10-K filings of NVIDIA and Berkshire Hathaway in PDFs, allowing us to ask questions and quickly extract key financial and strategic insights.
Investors, analysts, and researchers benefit from this approach by bypassing manual document review and accessing accurate, up-to-date information through natural language queries - all within their Kubernetes cluster!
Stepping through this finance cookbook
example,
you can port-forward the RAGEngine service to access your endpoint locally,
and specify the context of the 10-K filings index as follows:
kubectl port-forward svc/ragengine-llm-d 8000:80
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"index_name": "10-k",
"model": "meta-llama/Llama-3.1-8B-Instruct",
"messages": [
{
"role": "user",
"content": "What was the revenue of NVIDIA from 2024 to 2025?"
}
], "max_tokens": 100
}' | jq -r '.choices[0].message.content'
Which results in the output:
According to the provided documents, NVIDIA's revenue for the years
ended January 26, 2025 and January 28, 2024 were:
* Year Ended January 26, 2025: $130,497 million
* Year Ended January 28, 2024: $60,922 million
This looks accurate, when compared to Page 38 of NVIDIA’s 10-K:
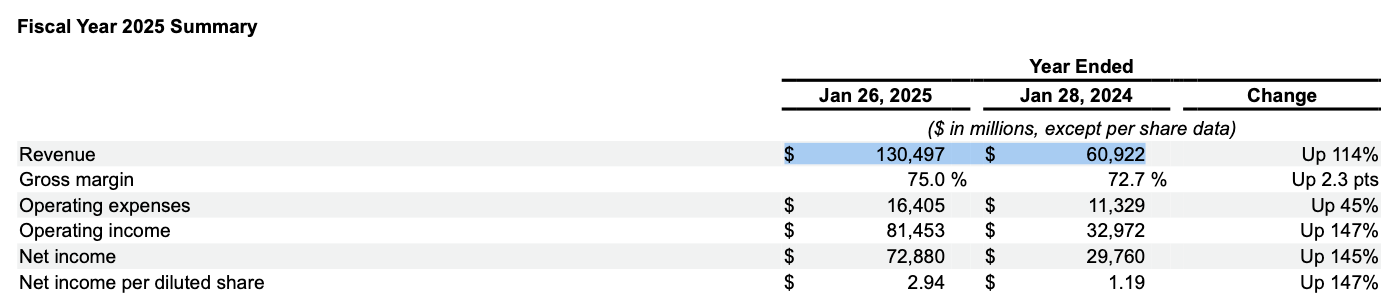
Let's take it one step further and request a more complex summary from Berkshire Hathaway context in our request:
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"index_name": "10-k",
"model": "meta-llama/Llama-3.1-8B-Instruct",
"messages": [
{
"role": "user",
"content": "Summarize Warren Buffett’s letter in BRK-B’s latest 10-K."
}
], "max_tokens": 200
}' | jq -r '.choices[0].message.content'
We get the following response:
In his letter, Warren Buffett discusses Berkshire Hathaway's
performance and strategy. He notes that the company has made
mistakes, but emphasizes the importance of acknowledging and
correcting them. Buffett highlights Berkshire's core business,
property-casualty insurance, and its unique financial model.
He also shares a personal anecdote about Pete Liegl, the founder
of Forest River, and explains Berkshire's approach to investing
in both controlled businesses and marketable equities.
We can also verify this response by looking at the story of Pete Liegl on Page 6 of BRK-B’s 10-K:

Great! We've built a system that makes it easy to search and understand complex financial documents, just by asking questions in plain English. Instead of manually combing through hundreds of pages, analysts and researchers can now get clear, accurate answers in a matter of seconds. Behind the scenes, this llm-d inference and KAITO RAGEngine system is designed to handle large and complex documents quickly and efficiently, giving fast responses even when many people are using it at once.
Next steps
Now that you've deployed an OpenAI-compatible endpoint using llm-d and integrated it with KAITO RAGEngine on AKS, you're well-positioned to scale this setup for enterprise use cases. Here’s how to continue building on what you’ve learned:
- Dynamically scale your llm-d inference by creating a
Kubernetes Event-Driven Autoscaling
(KEDA)
ScaledObjectbased on key vLLM metrics. - Introduce an automated data processing pipeline to index more extensive data efficiently as your RAG system grows over time.
- Stay up-to-date on the latest releases of the the llm-d project!